Documentation Index
Fetch the complete documentation index at: https://mage-staging.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
Introduction
Each streaming pipeline has three components:- Source: The data stream source to consume message from.
- Transformer: Write python code to transform the message before writing to destination.
- Sink (destination): The data stream destination to write message to.
In version
0.8.80 or greater.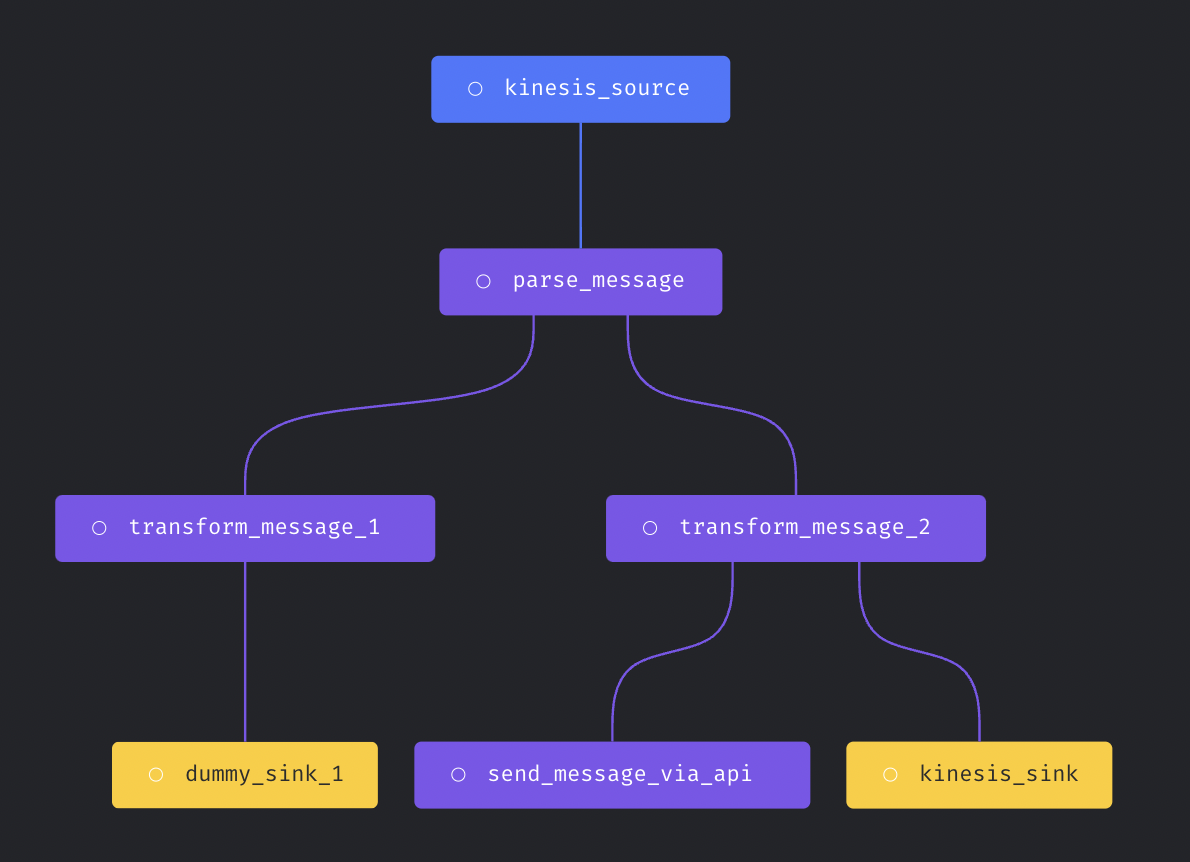
Supported sources
Supported sinks (destinations)
- Amazon S3
- BigQuery
- ClickHouse
- DuckDB
- Dummy
- Elasticsearch
- Kafka
- Kinesis
- MongoDB
- Microsoft SQL Server
- MySQL
- Opensearch
- Postgres
- Redshift
- Snowflake
- Trino
Test pipeline execution
After finishing configuring the streaming pipeline, you can click the buttonExecution pipeline to test streaming pipeline execution.
Run pipeline in production
Create the trigger in triggers page to run streaming pipelines in production.Executor count
If you want to run multiple executors at the same time to scale the streaming pipeline execution, you can set theexecutor_count variable
in the pipeline’s metadata.yaml file. Here is an example:
Executor type
When running Mage on Kubernetes cluster, you can also configure streaming pipeline to be run on separate k8s pods by settingexecutor_type
field in the pipeline’s metadata.yaml to k8s.
Example config: